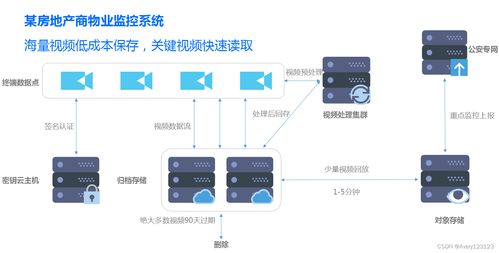
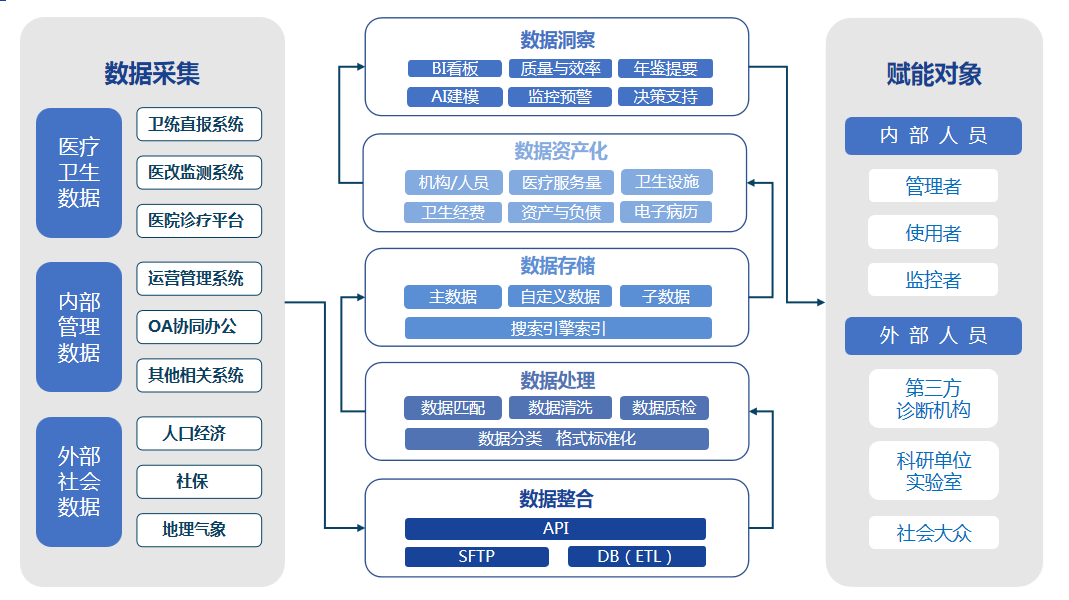
Hadoop 海量数据存储与计算的基石,数据处理与存储的强大支撑
在当今信息爆炸的时代,企业每天都会产生PB甚至EB级别的数据,如何高效、可靠且经济地存储和处理这些海量数据,已成为一项核心挑战。Apache Hadoop应运而生,作为一个开源的分布式系统基础架构,它从根本上解决了海量数据的存储和计算问题,并为此提供了一套完整的、可扩展的数据处理和存储支持服务。
一、 解决海量数据存储问题:HDFS
Hadoop的核心组件之一——Hadoop分布式文件系统(HDFS),是其存储能力的基石。HDFS的设计哲学是将超大规模文件(如TB、PB级)以数据块的形式,分布存储在由成百上千台廉价商用服务器组成的集群中。这种设计带来了多重优势:
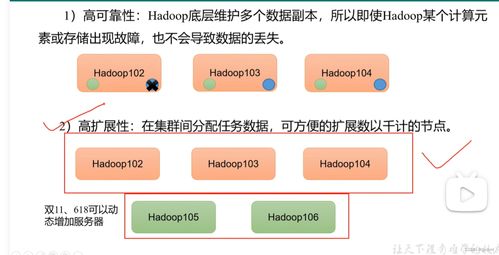
- 高容错性:数据被自动复制成多个副本(默认3份),并存储在不同节点上。即使单个或少数节点发生故障,数据也不会丢失,系统依然可以正常运行。
- 高吞吐量:数据访问采用“一次写入、多次读取”的模式,并支持大规模数据的流式读取,非常适合大数据分析场景,而非低延迟的交互式访问。
- 可扩展性:存储容量和计算能力可以通过简单地增加集群节点来线性扩展,满足数据量不断增长的需求。
- 经济性:Hadoop集群可以构建在廉价的商用硬件上,相比传统的大型机和高端存储,成本大幅降低。
二、 解决海量数据计算问题:MapReduce与YARN
存储问题解决后,如何在这些海量数据上执行复杂的计算任务?Hadoop提供了其经典的编程模型和计算框架。
- MapReduce编程模型:这是一种“分而治之”的思想。它将复杂的计算任务分解为两个主要阶段:Map(映射)和Reduce(归约)。在Map阶段,任务被并行化处理,每个节点处理其本地存储的数据块;在Reduce阶段,Map阶段的中间结果被汇总,产生最终结果。这种模型将计算任务移动到数据所在节点,极大地减少了数据在网络中的传输,非常适合批处理作业。
- YARN资源调度器:在Hadoop 2.0之后引入的YARN(Yet Another Resource Negotiator),将资源管理与作业调度/监控功能分离,成为一个通用的集群资源管理平台。它允许多种数据处理框架(如MapReduce、Spark、Flink等)共享同一个HDFS集群上的数据和计算资源,极大地提升了集群的利用率和多任务并发处理能力,使Hadoop从一个单一的计算系统演变为一个企业级的数据操作系统。
三、 完整的数据处理与存储支持服务生态
Hadoop不仅仅是一个存储和计算框架,它已经发展成为一个功能丰富的生态系统,围绕HDFS和YARN,提供了全方位的数据服务支持:
• 数据采集:Sqoop用于在Hadoop与传统关系型数据库(如MySQL、Oracle)之间高效传输批量数据;Flume用于高效收集、聚合和移动海量日志数据流。
• 数据管理与仓库:Hive提供基于SQL的数据查询与分析功能,将复杂的MapReduce程序简化为类SQL语句,降低了使用门槛;HBase是一个构建在HDFS之上的分布式、可扩展的NoSQL数据库,支持对海量数据的实时随机读写。
• 数据处理与分析:除了MapReduce,Spark凭借其内存计算和DAG执行引擎,提供了更快的迭代计算和流处理能力;Pig提供了一个高级脚本语言平台,用于简化MapReduce编程流程。
• 协调与管理:ZooKeeper为分布式应用提供高可用的协调服务,如配置维护、命名服务、分布式同步等,是许多Hadoop组件(如HBase)稳定运行的基础。
• 工作流调度:Oozie用于管理和调度复杂的Hadoop作业工作流,可以将多个MapReduce、Pig、Hive等任务串联起来顺序执行。
Hadoop通过其核心的分布式存储(HDFS)和资源调度(YARN)架构,结合丰富强大的生态系统工具,构建了一个完整、健壮且经济高效的海量数据处理与存储解决方案。它使得企业能够存储过去难以想象规模的数据,并能够从中挖掘出宝贵的业务洞察,真正将“数据资产”的价值最大化,成为驱动现代数据驱动型决策和智能化应用的坚实后盾。
如若转载,请注明出处:http://www.fmavip.com/product/4.html
更新时间:2026-06-18 07:32:14